
All large products are born as monoliths. It is easy, quick to start and to rationale about. But time adds pressure. Increased number of users, increased code, increased developers. At a certain point, the weight kills the release speed and uptime. Research indicates that, in monolith teams, it can take up to 40% of the time before a team can ship a feature than it does before it manages to resolve a merge conflict. It is then you have to consider slicing it open. Continue reading, this guide demonstrates the way to pull it off.
The Breaking Point: When Monoliths Stop Scaling
Early growth is well managed by a monolith. However, when the traffic is doubled or teams are increased, the cracks are visible. A schema tweak withholds an entire release. Scaling refers to cloning all of the stack, and not a single hot path. Incidents are more time consuming since all that is entangled. In polls, 2/3 of engineering heads claimed that their monolith slowed the process of delivering features as soon as the user traffic exceeded one million monthly sessions. Look for these warning signs:
- Deploys block every team and last hours.
- Scaling eats cash because you copy the full app.
- One bug drops the whole system, no isolation.
Boundaries of Domains and Right-Sized Services
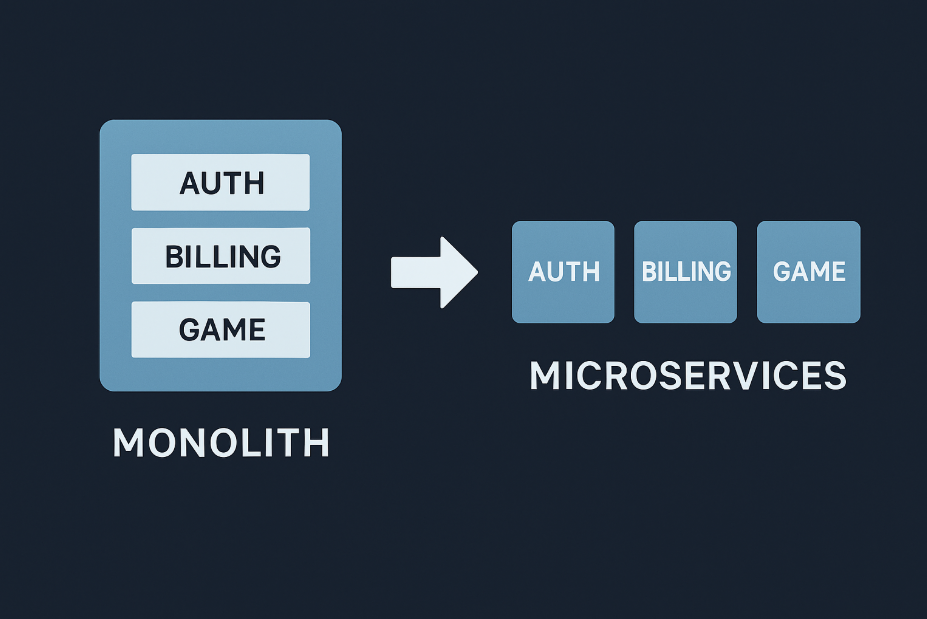
Breaking a monolith entails seeking seamless divisions. Areas such as auth, billing, or notifications are convenient as independent services. You may see at the game Lightning Storm to see how the system operates. The game features exciting bonus rounds and multipliers, plus the in-game purchases, leaderboards and matchmaking work well as independent services. The matching scales up when there is peak play, leaderboards are able to handle the async and purchases are able to remain constant. The domains are not scaled equally and teams do not step on one another. That is the advantage of domain cutting.
And when you divide, do not rebuild. Smaller, specialized services are less difficult to sustain. Shun mini-monoliths behind new APIs. Services ought to possess their data and logic without stealing too much. Keep them sharp and lean.
Async Messaging vs. Synchronous APIs
Services need to talk. The simplest one is synchronous APIs. Call, wait, respond: it is simple but introduces delay and connectivity. Async messaging modifies the flow. Services fire events and others respond when prepared. It deals with spikes and maintains loose systems. Here’s where each shines:
- Login or payments are compatible with synchronous APIs.
- Async messaging is a fit to logs, metrics or chat events.
- Mixed arrangements encompass checkout or fraud detection.
This is supported by industry statistics. Systems which included messaging recorded up to 30% reduced average response time under load than pure API calls. Teams usually blend the two. Critical sync path API, heavy firehose traffic API. Such a balance is optimal in production.
Dataper Service and Consistency Trade-offs
Microservices refer to numerous databases. Each service owns its state. That slices schema lock-ins, but introduces new issues. Joins disappear and consistency is weaker. You shift from strong to eventual. Dealing with conflicts is a factor of work.
Teams tend to take the form of event sourcing of audit logs or counters with CRDTs. SQL sits under money flows. NoSQL powers feeds and logs. When implemented at mass scale, companies that adopted per-service databases reported 99.95% uptime compared to 99.7% with shared monolith databases. You acquire uptime and scale, lose instant joins.
Observability: Tracing, Metrics, Logging
Gone are those days of debugging a single large log file. Now you must have good observability. Distributed tracing traces services. Measures include throughput, latency and failures. The logs record context when everything goes wrong. Without these, you’re blind. The three must-haves in this case are:
- Service tracing watches hopping.
- Measures of latency, error rates, throughput.
- Deep diving and audit logs.
A SaaS report noted that teams that were observable completely reduced mean time to resolution by 43%. Examples of popular tools include OpenTelemetry, Prometheus, and Grafana. They make ops life sane.
Migration Playbook: Strangler Fig in Practice
You do not take out a monolith with a single strike. The playbook is the Strangler Fig pattern. Enclose the monolith with a gateway. New features to microservices. Retire old modules slowly. With the course of time, the monolith is reduced to nothing. Here’s a table with the steps:
| Step | Action | Result |
| Wrap | Put an API gateway around monolith | Control all entry points |
| Redirect | Route new features to services | Monolith load shrinks |
| Isolate | Move domains with their own data | Services decouple, safer deploys |
| Retire | Turn off old modules | System becomes service-only |
This gradual replacement prevents downtimes and disruption. A 2024 case study revealed that this method enabled fintech to reduce risk by 60% percent. Users barely notice. Teams are able to have room to ship without months of wait.
Summary: Microservices Without Mayhem
Microservices alleviate scaling suffering but introduce operations. The trick is to cut intelligent domains, not arbitrary ones. Select the most appropriate combination of APIs and events. Accept data trade-offs and design for them. Bake observability early. Migrate, not a rewrite, with a strangler fig. Do it right, and you’ll scale seamlessly. The statistics are true: teams that have gone through this process have reported a 25-40% reduction in delivery times. This is how you can make production smarter and your team successful.











